2016isback.com
It was 1st of January, I was travelling back in the train to home from my friend’s place after New Year’s Eve. While I lifelessly looked at the black void in the window, I had an idea. A simple idea inspired by Instagram Reels and this trend of living like we’re back in 2016, so doing random stuff, having as much fun as possible etc. The plan was simple. I wanted to relive 2016 radio. Not a static playlist, but a living, breathing radio station that plays exactly what was topping the charts in Poland and the US exactly ten years ago. It was supposed to be a weekend script at worst.
Welp, I ended up in a multi-day struggle with Google’s rate limits, a headless agentic LLM, and the realization that “duration” is a pretty important concept when you don’t want a minute of dead air between Maroon 5 songs.
The Vision
So basically the idea was to create a page + background server. The page would be a simple landing, with two links to playlists on Spotify and YouTube. Those playlists would be changed daily by the server to match more or less what could have played in the radio in 2016.
How the page would have looked like if not for the Corporations
D in ABCDE stands for Delegate
I started with odsluchane.eu. It’s an unprecedented goldmine. It has minute-by-minute radio data for Poland, which for other countries is paid or not available at all unless you’re some corporate entity that got approved in the Music Industry Cartel. I used an agentic LLM (OpenCode.ai) to write the scraper. After linking my OpenRouter API key and hitting it with Gemini 3 Flash, it was doing its thing.
The total cost? $0.499. It was worth every penny to avoid an hour of writing regex for messy HTML tables and then switching the approach to HTML parsing library while trying to find proper XPath… I grabbed 2015 and 2016 data, I needed to know what played before the radio station “starts” to get those propagation graphs otherwise, I would need to treat every song that played in 2016 as new, with 2015 I know what was released already.
I also grabbed Billboard data for the USA, but it was just a weekly CSV. Compared to the minute-by-minute beautiful data of the Polish logs, the American data felt vague at best. I ended up dumping everything into SQLite because CSV files stop being fun after the first million rows.
Airwave Marketshare Fun Fact (totally necessary)
| Station | 2015 (%) | 2016 (%) |
|---|---|---|
| RMF FM | 24.90 | 24.50 |
| Radio ZET | 13.70 | 13.60 |
| Jedynka | 9.50 | 8.80 |
| Trójka | 7.80 | 7.90 |
| Radio Eska | 7.20 | 6.70 |
I stole it from some site, and used it while generating the song order for the radio. We want to match the tastes of the people.
Data Mining Time: Song Propagation
For a long time I believed that song popularity would follow a nice, clean linear curve. It would start slow, peak, and then fade away into the obscurity with some visits from time to time.
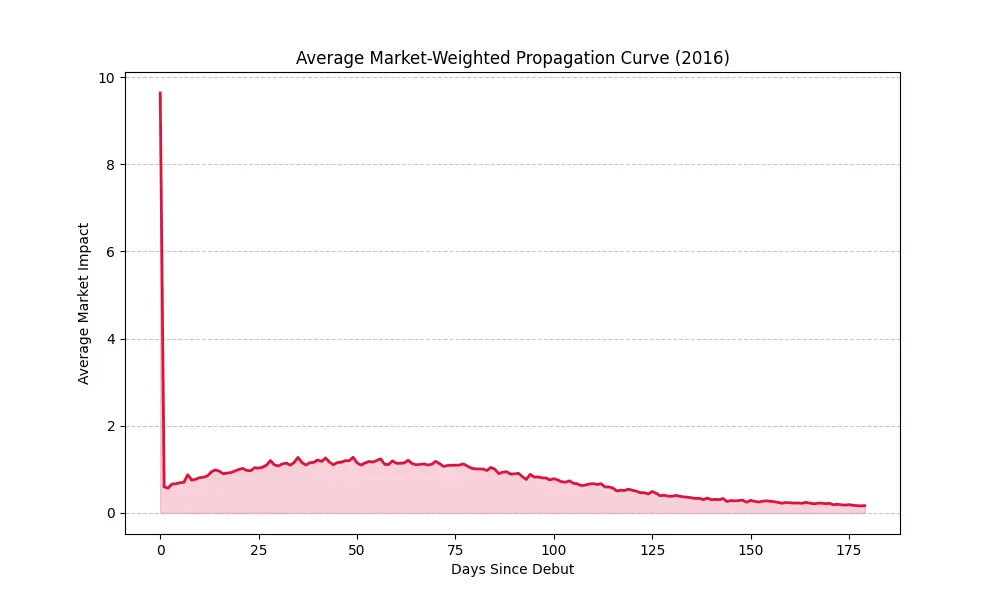
Good to know.
The data is erratic. It’s bouncy. A song will dominate for three days, get much less played for a week or more because the station programmers got bored, and then surge back. I wonder why, actually?
Data Mining Time: Top Weighted Songs
I didn’t just want to play songs randomly. I wanted to play what was actually popular. I implemented a weighting system based on frequency and station reach.
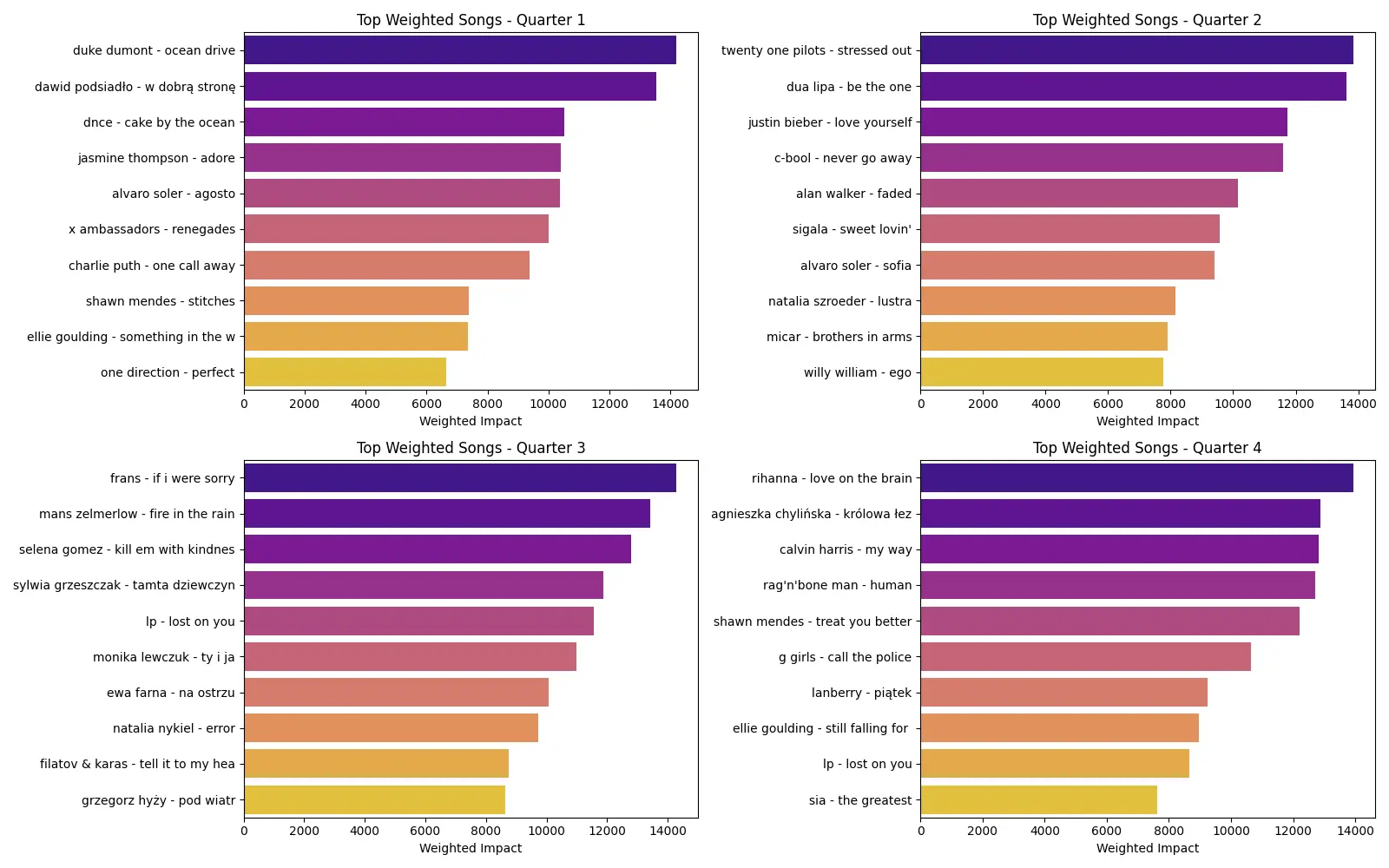
If a song played 50 times a day on RMF FM, it gets a massive weight. This makes the “radio” feel real, you hear the hits relatively often, but the deep cuts still show up to keep it honest. Works quite fell if you ask me.
For funsies, here is market-weighted propagation for top 10 new songs. I’ve used 7 day moving average, basicallly higher is more popular.
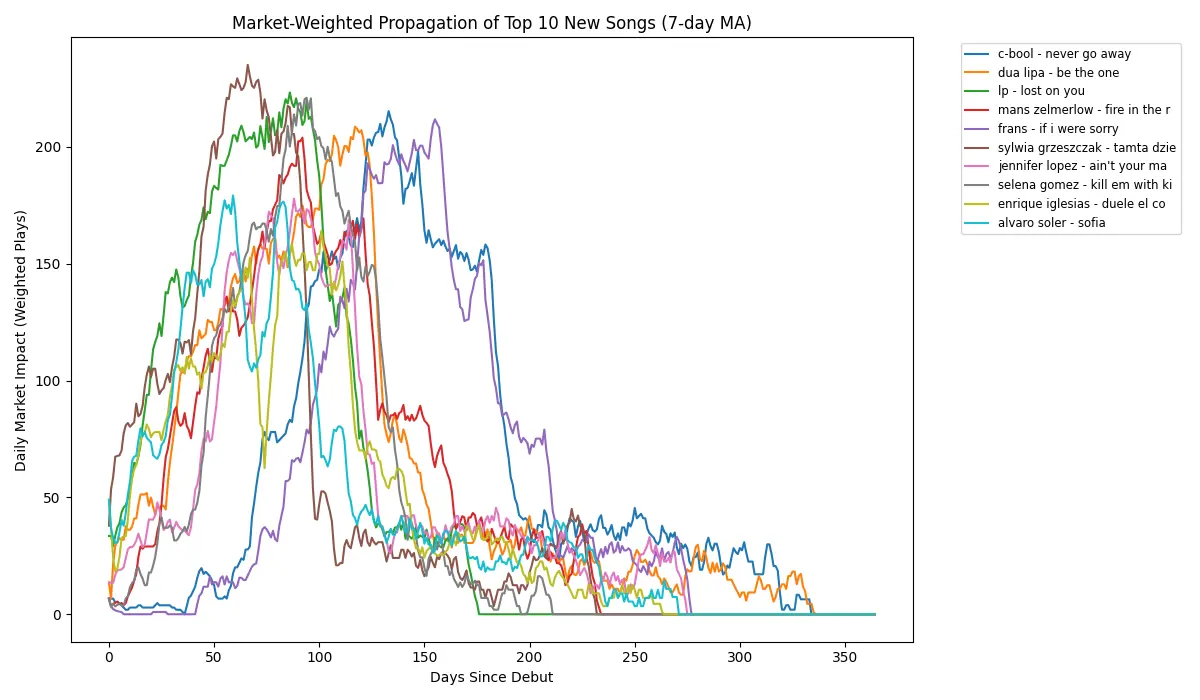
Some songs are popular later than others, but still follow very similar curve of major peak, downfall, another peak. Repeated until death.
The YouTube Quota Wall
This is where the real trouble started. I tried doing this the “proper” way, using the YouTube Data API.
I hate Google Cloud Platform.
Here is the math: A single search costs 100 quota units. I need to resolve about 300 songs per “day” of radio. That’s 30,000 units just for the basics, plus overhead. My daily limit? 10,000 units.
I blew through my entire quota in minutes.
Even when it worked, the metadata mismatch was terrible. Searching for Silento - Watch Me (Whip / Nae Nae) would often fail or return a 10-hour loop version because the API gets confused by the brackets. I needed a better way.
The yt-dlp is the GOAT
I ditched the API. I fired up yt-dlp. I thought I could just search and grab the IDs.
yt-dlp --get-id 'ytsearch2:Maroon 5 - Don't Wanna Know'
It worked for a bit. Then YouTube decided I was a bot (pretty accurate if you ask me) and, also, some songs are age restricted?. I had to feed it cookies, wait an hour for it to “think about itself,” and pray. It took from the 15th to the 19th of January just to resolve the links.
C# Backend
The original logic was in Python, but I missed the type safety, and I didn’t want to use Python for this project. I had the AI rewrite the generator into C#.
It’s been a while since I touched C#. Everything is different. The Main class is gone (thanks, top-level statements). Autocomplete in VS Code just died. Fortunately, switching to Rider saved my sanity (for a second I thought about coming back to Python). A few minutes of porting later, the API was alive.
I could have guessed…
I shipped it via Docker. It looked great. I used Antigravity for the frontend, which handled the visuals perfectly. So good in fact, I am slightly scared for the friends on the frontend side. Although I still wouldn’t allow AI to write entire SaaS for me, at least not without constant reading of the code it generated. I don’t trust it that much yet.
Time to listen to it…
I’d play a song, and then… nothing. Just silence for a full minute. I realized I had the YouTube IDs, but I didn’t have the actual video durations in my database. My transition logic was guessing based on the average song length, and it was guessing wrong, most of the time.
I had to go back to the well. Another round of yt-dlp, but with --get-duration this time for every single link. It was slow. But it fixed the gaps. The page was up before this duration fix, so I had to do a dirty fix by averaging the song length and hoping it would be good. Well, it was listenable.
It Works (Mostly)
The site is live at 2016isback.com. It’s just a YouTube player pulling from a database that thinks it’s a radio station. It’s less than ideal. But hey, for $0.50 and a week later, I’ll take it.
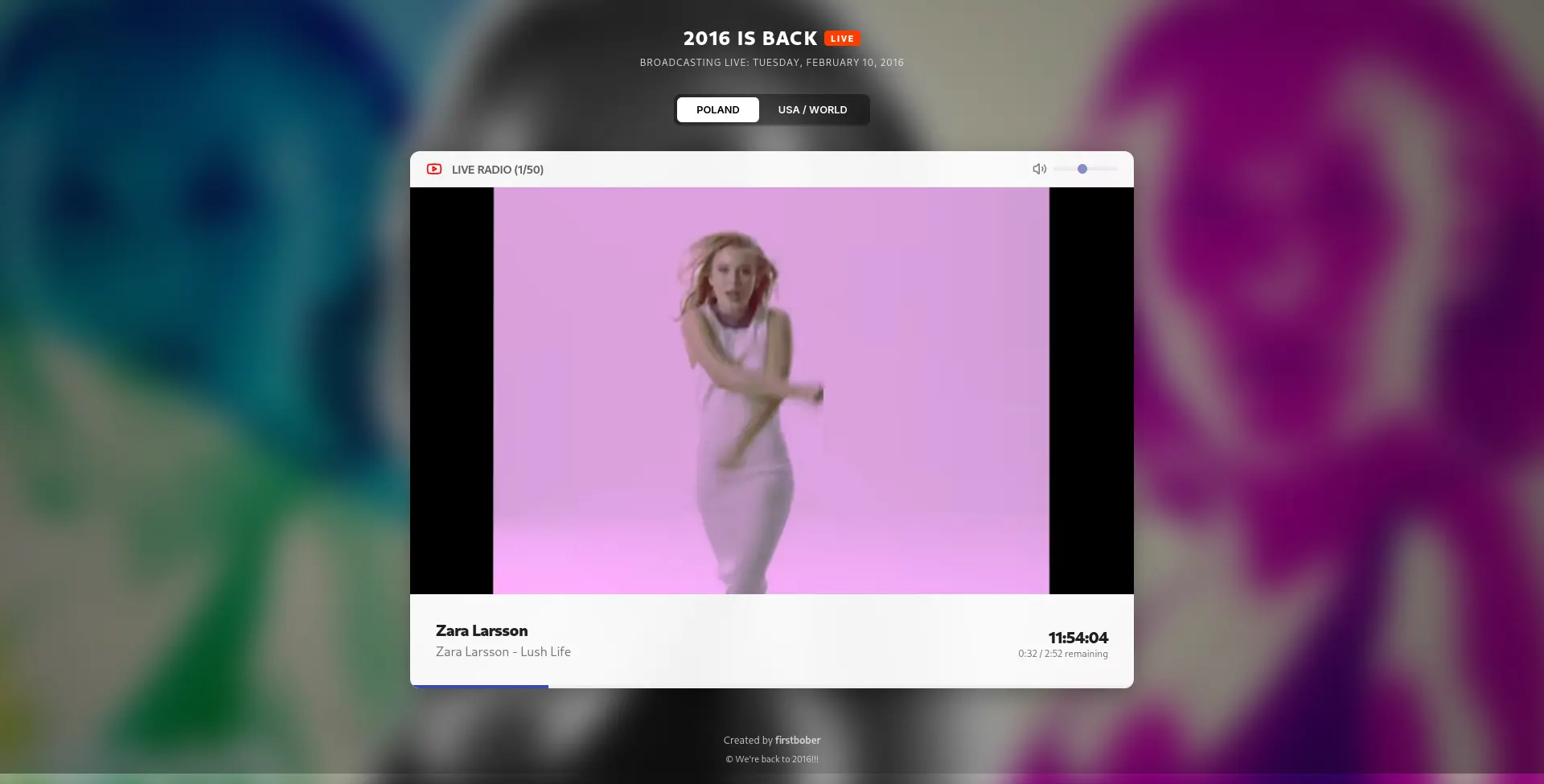
Looks pretty good!
comments powered by DisqusBefore making this post, I sent the page to a few friends, one of them overseas with much different timezone, guess what, it was fucked up ;) Quick fix later it works now. I guess no matter how much technology and knowledge you have, timezones will always find a way to go back to the code and do some fixes.